
ORM vs Raw Query / N+1 Problem
수 많은 정보가 저장되는 Data Base에서 원하는 정보를 얻기 위해서는 Query문을 작성해야 한다.
간단하게, single 테이블에서 정보를 가져오기도 하고 좀 복잡하게는 여러 join문을 이용하여 여러 테이블에서 정보를 가져올 수 도 있다.
현업에서는 다양하고 복잡한 Query문 작성이 요구되고 SQL에 능숙해지기까지 많은 시간이 걸린다.
그리고 꼬리에 꼬리를 무는 Query문에서 작은 실수는 디버깅을 힘들게 만든다.
이를 해결해줄 도구가 ORM이다.
ORM(Object - Relational Mapping)은 관계형 데이터베이스와 객체 사이를 매핑시키는 것을 말한다.
ORM은 객체 지향 언어를 사용하여 데이터베이스에 접근할 수 있는 여러 method들을 제공해준다.
ORM이 매핑 시켜놓은 객체를 통해 데이터베이스 데이터를 다룰 수 있게 되는 것이다.
그럼 ORM에 대해서 본격적으로 알아보자!
ORM의 장점
-
Code와 Database 간의 종속성 DOWN
DB 위에 하나의 추상화된 층을 쌓는 것이기 때문에 개발자들이 MySQL, PostgreSQL, SQLite…등 DB간의 사소한 차이들을 일일이 몰라도 된다. - SQL Query 작성 부담을 덜 수 있다.
인터페이스 작성에 할애하는 시간을 비지니스 로직에 쏟을 수 있다. 직관적 쿼리 => 에러, 버그 발생 가능성 DOWN, 가독성 UP - 재사용 및 유지보수에 용이하다.
ORM의 단점
-
실행 속도가 잘 짜여진 raw query보다 느리다.
-
한정된 명령문으로 인한 한계
-
추상화로 인해 Low level 디버깅이 불편함
-
ORM은 주로 library나 framework, API 형태로 제공되기 때문에 ORM에 종속되게 되고 다른 solution으로의 이동이 어려워진다.
Raw Query의 장점
-
Best Performance를 달성할 수 있다.
-
ORM을 사용할 때보다 디버깅이 편하다.
-
third-party code에 대한 종속성이 없다.
Raw Query의 단점은 위에 적었으니 따로 적지 않겠다.
여기까지 읽어보면 사실 ORM의 단점이 곧 Raw Query의 장점이고 ORM의 장점이 곧 Raw Query의 단점이다.
그래서, SQL query문에 능숙하다는 전제하에 정답은 없고 주어진 task 환경에 맞추어 어떤 방법을 사용할지 선택해야 한다. SQL에 익숙하지 않으면 ORM…
N+1 Problem
ORM은 N+1 문제라는 대표적인 Anti - pattern을 가진다.
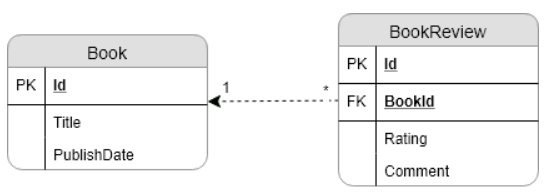
위 그림과 같은 관계 모델에서 DB에 있는 모든 Book을 차례로 불러와 (iterative) 책마다 달려있는 BookReview에 접근한다고 생각해보자.
여기서 ORM은 default가 lazy-loading (정말 필요한 시점에만 SQL을 호출한다)이기 때문에, 아래와 같이 진행될 것 이다.
SELECT * FROM Books;
for each Book
SELECT * FROM BookReview WHERE BookId = ?
결과적으로 1번의 Books를 가져오는 SELECT문과 N번의 추가적인 SELECT문이 필요하다.
만약, Book이 100개 있다면 BookReview SQL은 100번 호출된다.
Query를 한번 날릴 때 마다 오버헤드가 발생하기 때문에 Query문 100 개에 1개의 정보를 return받는 것 보다 Query문 1개에 100개의 정보를 return 받는 것이 훨씬 빠르다.
이 차이는 DB가 다른 machine에서 돌아가고 있을 때 더 극명해진다.
통신하는데 걸리는 속도가 1-2ms 라면, 100개의 Query를 날리는데 필요한 시간은 100ms-200ms다.
이 문제를 해결하기 위해서는 Eager-Loading을 사용하면 된다. Eager-Loading을 사용하면 사전에 쓸 데이터를 포함하여 쿼리를 날리기 때문에 비효율적으로 늘어나는 쿼리 요청을 방지할 수 있다.